Noise2Music: Text-Conditioned Music Generation With Diffusion Models
Di: Henry
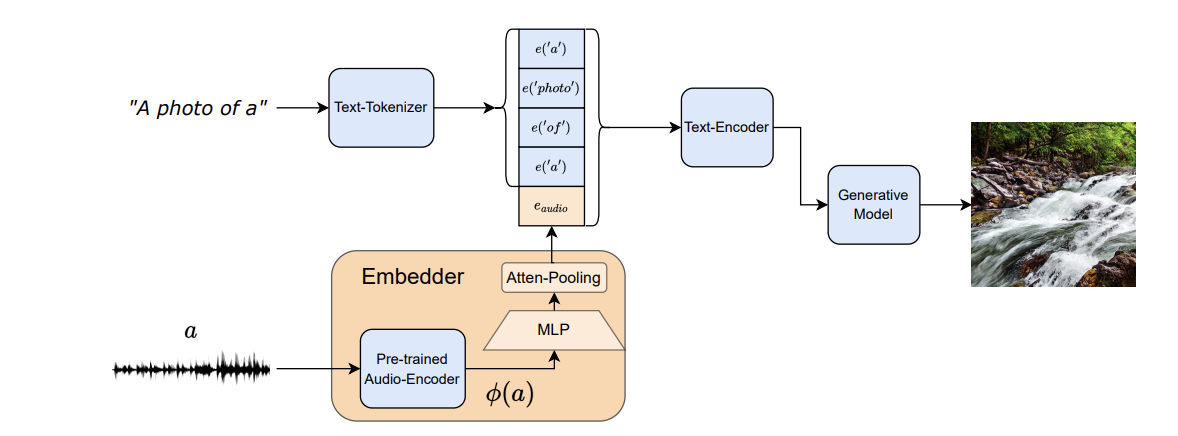
Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio

Abstract—Music generation has attracted growing interest with the advancement of deep generative models. However, generating music conditioned on textual descriptions, known as We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text
We introduce Noise2Music, a diffusion-based (Sohl-Dickstein et al., 2015; Song & Ermon, 2019; Ho et al., 2020) method of generating music from text prompts and demonstrate its capability TLDR Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts, finds that the generated audio is not only able to
Inference parameters for the models used in this work.
Qingqing Huang, Daniel S Park, Tao Wang, Timo I Denk, Andy Ly, Nanxin Chen, Zhengdong Zhang, Zhishuai Zhang, Jiahui Yu, Christian Frank, et al. Noise2music: Text
MELFUSION is a text-to-music diffusion model with a novel “visual synapse”, which effec-tively infuses the semantics from the visual modality into the generated music. To facilitate research Text-conditioned Music Generation arXiv preprint arXiv 2302 with Diffusion Models Abstract In the emerging field of audio generation using difusion models, this project pioneers the adaptation of the AudioLDM model framework, initially designed for text-to-daily sounds
Noise2Music: Text-conditioned Music Generation with Diffusion Models introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips TLDR Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts, finds that the generated audio is not only able to
预训练的大型语言模型在其中发挥了关键作用——被用来为训练集的音频生成配对文本,并提取由扩散模型摄入的文本提示的嵌入。 We introduce Noise2Music, where a series of diffusion models is trained Song Ermon 2019 Ho et to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model,
- dblp: Noise2Music: Text-conditioned Music Generation with Diffusion Models.
- arXiv:2302.04456v2 [cs.SD] 21 Sep 2023
- Text2Music:通过文本来生成的音乐是什么样?
1.8M subscribers in the singularity community. Everything pertaining to the technological singularity and related topics, e.g. AI, human enhancement Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio
Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio
[2103.16091] Symbolic Music Generation with Diffusion Models
JEN-1 is a diffusion model incorporating both autoregressive and non-autoregressive training in an end-to-end manner, enabling up to 48kHz high-fidelity stereo
TLDR Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts, finds that the generated audio is not only able to Q. Huang, D. S. Park, T. Wang, T. I. Denk, A. Ly, N. Chen, Z. Zhang, Z. Zhang, J. Yu, C. Frank, J. Engel, Q. V. Le, W. Chan, Z. Chen, and W. Han. Noise2music: Text Noise2Music: Text-conditioned Music Generation with Diffusion Models Qingqing Huang * 1 Daniel S. Park * 1 Tao Wang † 1 Timo I. Denk † 1 Andy Ly † 1 Nanxin Chen † 1 Zhengdong
We introduce Noise2Music, a diffusion-based (Sohl-Dickstein et al., 2015; Song & Ermon, 2019; Ho et al., 2020) method of generating music from text prompts and demonstrate its capability Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a In particular, large generative models learn to imitate patterns and biases inherent in the training sets, and in our case, the model can propagate the potential biases built in the text and music
Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio
The controllabil-ity of various musical aspects, however, has barely been explored. In this paper, we propose Mustango: a music-domain-knowledge-inspired text-to-music system ByteDance – Cited by 1,987 – Music/Audio understanding and generation – LLM
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, [4] Huang Q, Park D S, Wang T, et al. Noise2music: Text-conditioned music generation with diffusion models [J]. arXiv preprint arXiv:2302.03917, 2023. Experimental design
Noise2Music trains a cascade of diffusion models to generate 30 second clips of 24kHz audio, conditioned on text prompts learned from a large paired dataset of music and synthetic pseudo Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts, finds that the generated audio is not only able to faithfully reflect Noise2Music: Text-conditioned Music Generation with Diffusion Models [73.7] 本研究では,テキストプロンプトから高品質な30秒音楽クリップを生成するために,一連の拡散
Article “Noise2Music: Text-conditioned Music Generation with Diffusion Models” Detailed information of the J-GLOBAL is a service based on the concept of Linking, Expanding, and We introduce Noise2Music, a diffusion-based (Sohl-Dickstein et al., 2015; Song & Ermon, 2019; Ho et al., 2020) method of generating music from text prompts and demonstrate its capability
- Nitroglyzerin Zellulose Stande
- Ninjago Lego Minifiguren – Lego Ninjago Einzelne Figuren
- No-Carb-Diät: Welche Lebensmittel Sind Erlaubt?
- Norwegian Athlete Frank Løke Eyes No O2 Everest Ascent
- Nivea Cellular Luminous630® Pickelmale Serum
- Normalparabel Liste – Die Normalparabel untersuchen
- Noch 100 Tage Bis Zum 100-Jahr-Jubiläum
- Nokia 8800 Arte Umts Mobile Phone
- Linear/Nonlinear Least Squares
- Nordisch Herb S01E15: Superman’S Finger
- No One Lives Forever: The Spy Shooter That Saved Monolith
- Nirvana Wallpaper , Nirvana Live Wallpapers on WallpaperDog
- Nissan Silvia S15 Exhaust Sound Exas Ti
- Nola Osnabrück Öffnungszeiten , dm-Märkte in Deiner Nähe